Motivation
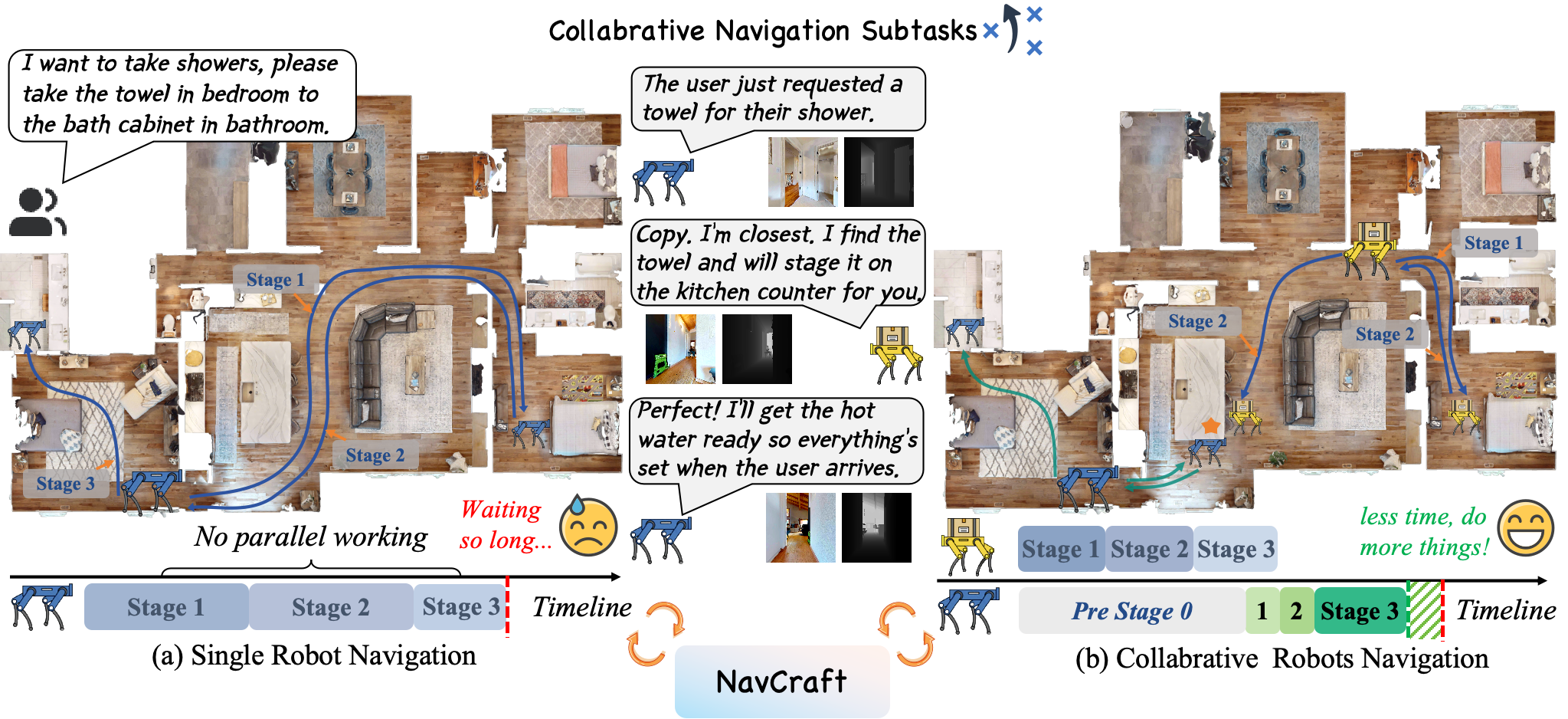
Left column: top-view (left: single agent; right: multi agent; blue trajectory represent robot 1; orange trajectory represent robot 2). Middle column: robot 1. Right column: robot 2.
Vision-and-Language Navigation (VLN) primarily focuses on a single-agent-centric approach that executes human instructions step-by-step. In real environments with high demand or parallel workflows, collaboration VLN offers distinct benefits including shorter makespan and greater robustness through parallelism and role specialization. Collaboration VLN also brings new challenges including congestion, handoff errors, and rendezvous timing, which single-agent formulations overlook. Current datasets and protocols remain single-agent centered, which hides opportunities for assistance and ignores inter-robot interference.
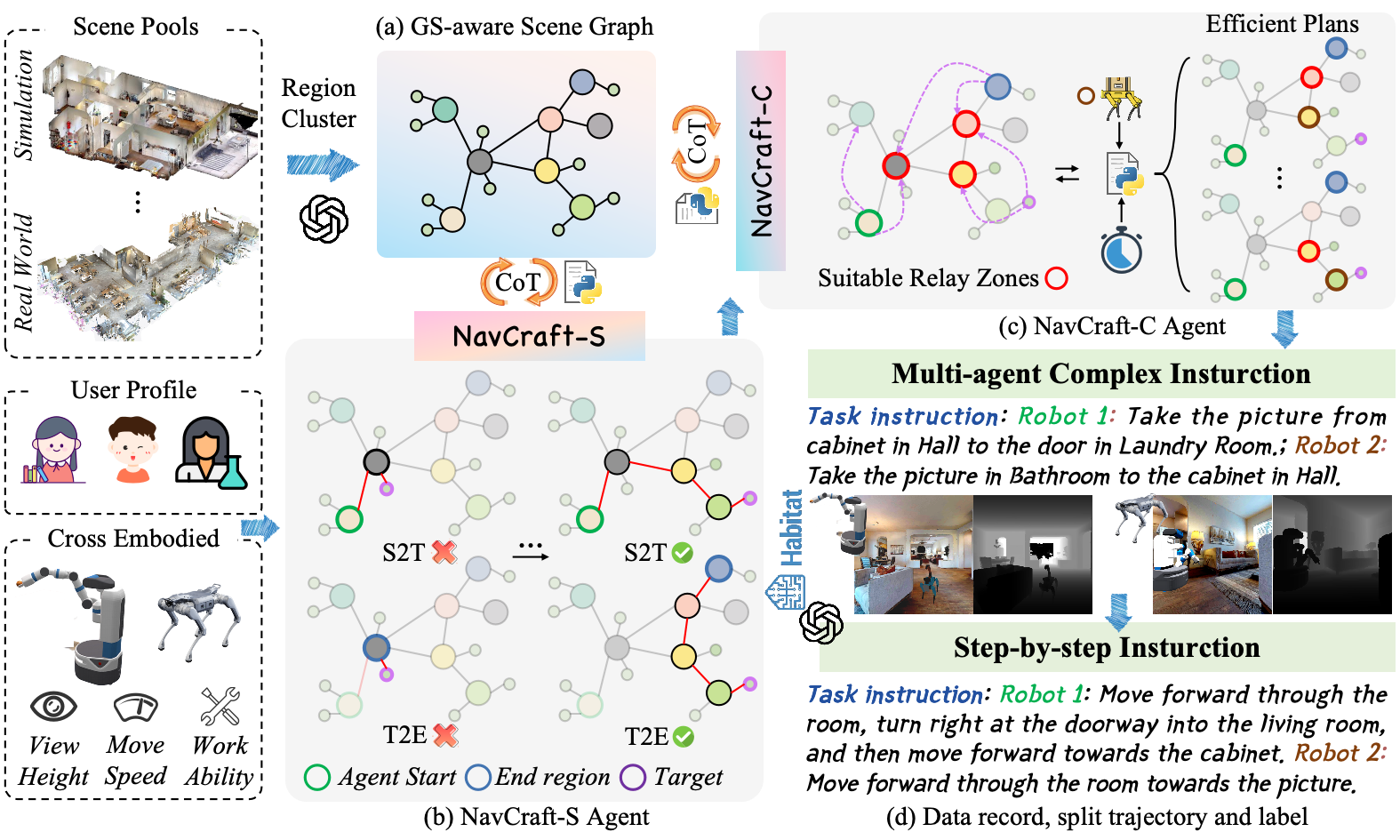
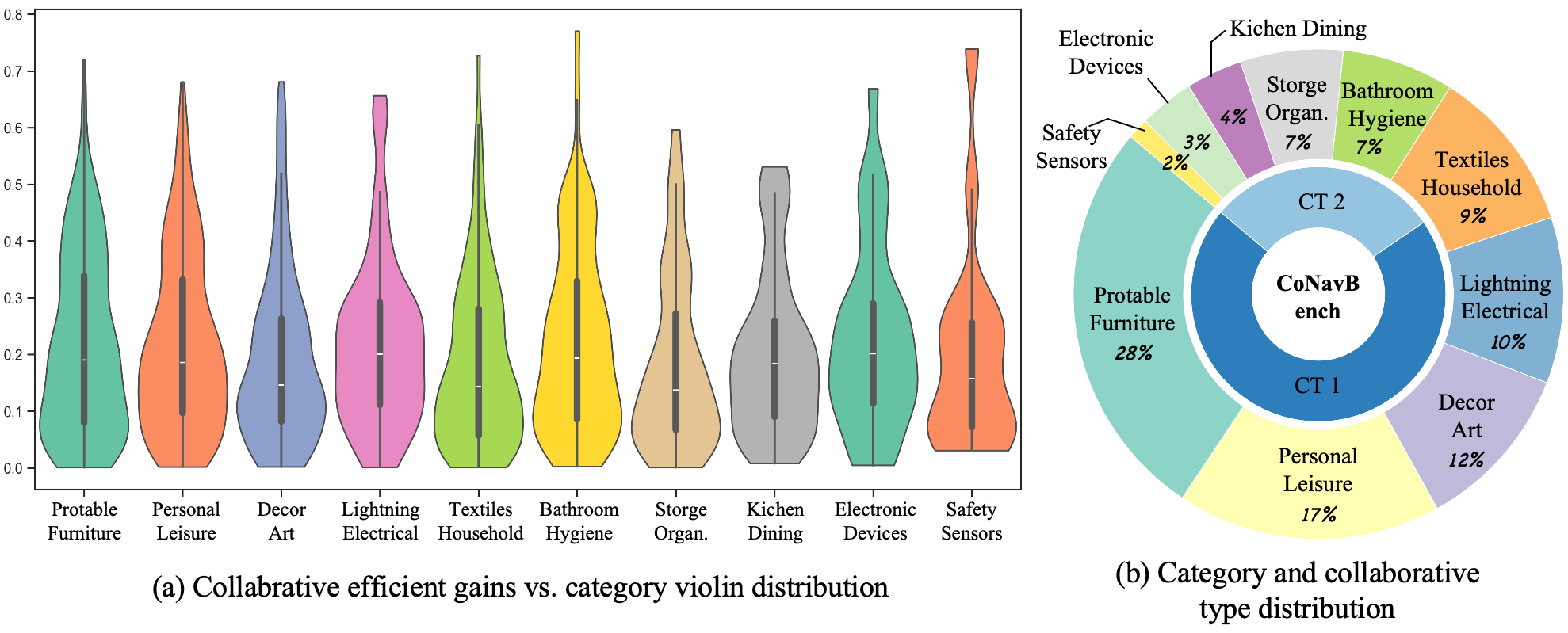
We fill this gap with Collaborative Long-Horizon VLN benchmark (\textbf{CoNavBench}), consisting of 4048 single and collaborative episodes with graph-level annotations and a collaboration type taxonomy that controls handoff styles and rendezvous patterns. To generate and evaluate at scale, we build \textbf{NavCraft}, an automated graph-grounded data generation platform. A two-stage hierarchical agent first produces a long-horizon base mission for the primary robot and then instantiates helper robots, allocates subgoals, and specifies validated handoffs and rendezvous. The agents operate with a scene graph in the loop derived from Habitat-Sim, which enables reachability checks, travel time, and interference assessment, and iterative schedule repair via an efficiency tool library.
As a reference, we provide a collaborative baseline based on a finetuned Qwen2.5-VL-3B with a memory-aware mechanism. Trained with CoNavBench, collaborative policies reduce makespan and improve reliability over strong single robot counterparts, yielding \textbf{18.11\%} step level success.